MySQL基础
MySQL的where条件查询是从左往右的。(Oracle的where是从右往左的)
select * from A, B ; 这是笛卡尔积
select * from A, B where a.id =b.aid; 这个结果必须是a表中的id 和b表中的aid完全相等的结果才会显示。
MySQL
innodb引擎数据和索引存储文件是一个 .ibd 表的定义文件是 .frm
myisam引擎数据和索引是分开存储的 .myi 索引文件 .myd 数据文件 .frm 表定义文件
| 存储文件 | Innodb | Myisam |
| - | - | - |
| 存储文件 | .frm 表定义文件.ibd 数据文件和索引文件 | .frm 表定义文件.myd 数据文件.myi 索引文件 |
| 锁 | 表锁、行锁 | 表锁 |
| 事物 | 支持 | 不支持 |
| CRUD | 读、写 | 读多 |
| count | 扫表 | 专门存储的地方(加where也扫表) |
| 索引结构 | B+ Tree 聚集索引 | B+ Tree 非聚集索引 |
| 外键 | 支持 | 不支持 |
此外还有存储引擎类型 Memory (数据主要在内存中,所以可能丢数据)、Archive(压缩存储)、CSV(基于CSV格式文件存储)
注:
同一个数据库也可以使用多种存储引擎的表。如果一个表要求比较高的事务处理,可以选择InnoDB。这个数据库中可以将查询要求比较高的表选择MyISAM存储。如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
MySQL是通过文件系统对数据和索引进行存储的。
MySQL从物理结构上可以分为日志文件和数据索引文件。
MySQL在Linux中的数据索引文件和日志文件都在/var/lib/mysql目录下。
日志文件采用顺序IO方式存储、数据文件采用随机IO方式存储。
顺序io [首地址/偏移量](适合日志)
优势: 记录速度快,只能追加
劣势: 浪费空间
随机IO [记录地址0x2133] (适合数据+索引)
优势: 省空间
劣势: 相对慢
[mysqld]
#MySQL设置大小写不敏感:默认:区分表名的大小写,不区分列名的大小写
#0大小写敏感 1:大小写不敏感
lower_case_table_names=1
#默认字符集
character-set-server=utf8
#开启慢查询日志(记录执行时间超过long_query_time秒的所有查询,便于收集查询时间比较长的SQL语句)
slow_query_log=ON
#慢查询的阈值
long_query_time=3
#日志记录文件如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名,但不是绝对路径名,文件则写入数据目录。
slow_query_log_file=file_name
查看日志开启情况
show variables like 'log_%';
查看数据文件
SHOW VARIABLES LIKE '%datadir%';
数据文件:
InnoDB:
.frm 主要存放与表相关的数据信息,主要包括表结构定义信息
.ibd: 使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件
.ibdata 使用共享表空间存储表数据和索引信息,所有表共同使用一个或者多个ibdata文件。
Myisam:
.frm: 主要存放与表相关的数据信息,主要包括表结构的定义信息
.myd: 主要存储表数据信息
.myi: 主要存储表数据文件中任何索引的数据树.
索引
数据结构可以查看以下链接
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B+Tree (数据都在叶子节点,并且叶子节点是个链表带顺序)
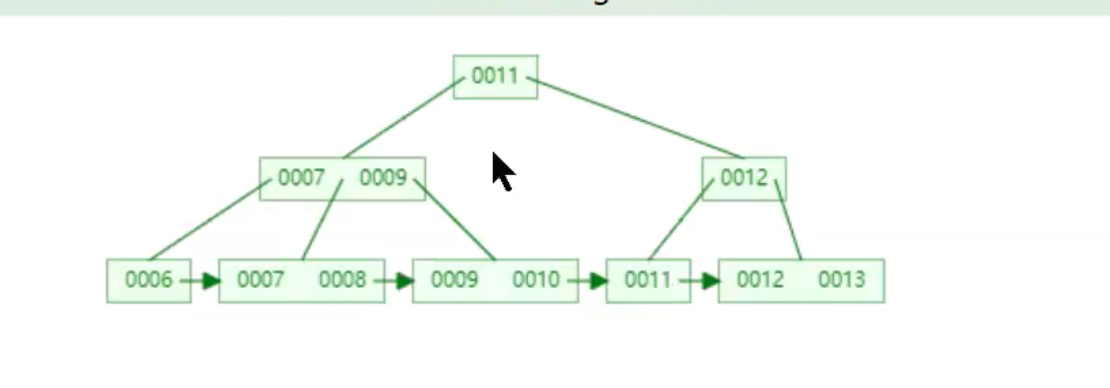
BTree
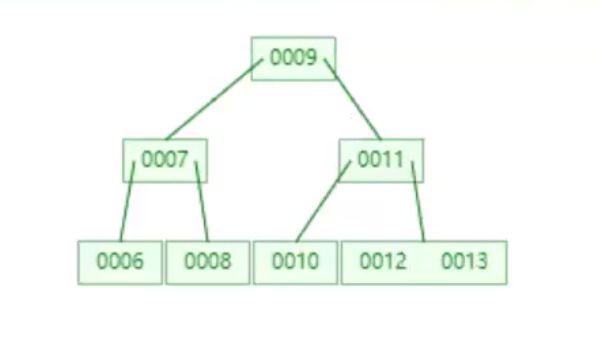
B树和B+树的最大区别是: 非叶子节点是否存储数据.
B树: 叶子节点和非叶子节点都会存储数据
B+树: 只有叶子节点才会存储数据,而且数据在一行上,数据都是有指针指向的,也就是有序的。
explain 执行计划
type列 会出现以下值,从好到坏依次:
system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery, index_subquery,range,index_merge,index,ALL
除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引, 应该最少要用到range级别
逻辑架构
connector -> conection pool
SQL Interface(接口) -- Parser(解析器) --- Optimizer (解析器) -- Cache(缓存【SQL语句hash值作为key,查询结果作为结果存储, mysql8.0以后不用缓存了】)
| 存储引擎 | 说明 |
| - | - |
| MyISAM | 高速引擎,较高插入、查询速度,但不支持事物、不支持行锁,空间和内存使用比较低 |
| InnoDB | 5.5版本以后的默认引擎,支持事物和行级锁定,事务处理、回滚、崩溃修复能力和多版本并发控制的事物安全,比MyISAM处理速度稍慢,支持外键 |
| Memory | 内存存储引擎,拥有极高的插入、更新和查询效率。但是会占用和数据量成正比的内存空间.只在内存上保存数据,意味着数据可能会丢失,数据安全性低,适用于不需要持久保存的数据 |
Myisam索引
由于是非聚集索引,数据文件和索引文件是分开存放的。所以索引树(.myi文件)上只存放地址。主键索引存的是数据的地址, 数据地址指向的是数据文件(.myd)中的位置。
InnoDB索引
由于是聚集索引,索引和数据在一个文件上。 数据就挂载到主键索引的叶子节点下面。

主键索引里面存的是数据, 辅助索引里面存的是主键值. 所以
如果是select * from user where name = '李四';
- 这条SQL是非主键查询,则需要搜索两次索引树(第一次是查辅助索引树通过name找到主键值,然后根据主键值再查主键索引树,这个动作就叫做【回表】),最终取出数据。 如果不想回表操作,那么则需要在第一次查询辅助索引树的时候就把所有字段(假如表有主键id,姓名name,和年龄age) 找到, 那么需要建立组合索引,将name 和 age 都挂载到辅助索引上,利用组合索引完成,叫做【覆盖索引】。
- 是否回表,主要看select的列是否都在辅助索引树的一颗树上面,如果查询的列都在这颗索引树上则不用回表。
问:
MySQL 在innodb中一个3层的B+树最多大概可以存放多少行数据?
首先,在innodb存储引擎里面,最小的存储单元是页(page),一个页的大小是16KB。这就说明了一个页的大小为16384B, 存放总记录数为:根节点指针数*单个叶子节点记录行数.
然后因为非叶子节点的结构是:“页指针+键值”,我们假设主键ID为bigint类型,长度为8字节(byte),而指针大小在InnoDB源码中设置为6字节(byte),这样一共14字节(byte),因为一个页可以存放16k个byte,所以一个页可以存放的指针个数为16384/14=1170个.
因为单个页的大小为16kb,而一行数据的大小为1kb,也就是说一页可以存放16行数据.
所以一个三层的B+树大概能存储的数据为
第一层1170个指针* 第二层1170个指针 * 每个page存储16行 = 21902400行记录
参考:
https://blog.csdn.net/qq_35590091/article/details/107361172